Comment lire et interpréter les paramètres d'une régression linéaire simple.
Comprendre les modèle linéaires, savoir lire les coefficients de la droite et distinguer les valeurs observées des valeurs estimées.
Présentation de la régression linéaire simple
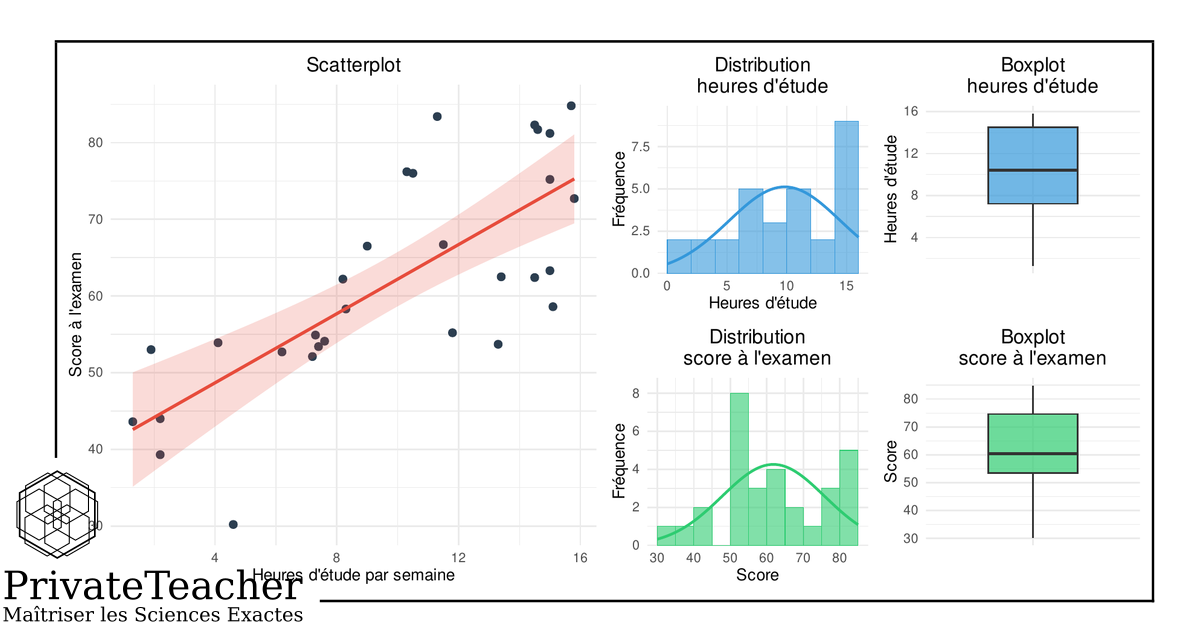
La régression linéaire simple est un modèle statistique qui met en relation deux variables quantitatives. Il s'exprime par une droite d'équation ŷ = b₀ + b₁x, où b₀ est l'ordonnée à l'origine et b₁ est la pente — le coefficient de proportionnalité entre le prédicteur et la variable dépendante. En psychologie, ce modèle permet de quantifier une association empirique, d'évaluer sa significativité et de produire des prédictions. La distinction entre valeurs observées (y) et valeurs estimées par le modèle (ŷ) est centrale à toute interprétation correcte.
Pourquoi utiliser la régression linéaire simple
La régression linéaire simple répond à des questions du type : le nombre d'heures d'étude permet-il de prédire le score à un examen ? La consommation d'alcool est-elle associée à la qualité du sommeil ? Le coefficient b₁ quantifie l'ampleur et la direction de l'association. La pente est le coefficient de proportionnalité entre les deux variables : c'est le paramètre clé du modèle. Le R² indique la part de variance expliquée. Le test de significativité détermine si l'association dépasse le bruit aléatoire attendu sous H₀.
À qui s'adresse ce document
Ce document cible les étudiants du Bachelor en Psychologie (filière francophone) à UniDistance FernUni Schweiz, en première année (BA1). À UniDistance, les méthodes quantitatives représentent 29 à 30 ECTS sur l'ensemble du Bachelor, ce qui traduit une priorité institutionnelle explicite pour la rigueur empirique. La régression linéaire est un outil évalué aux examens de méthodes : l'étudiant doit savoir lire une sortie JASP, interpréter les coefficients et formuler une conclusion conforme aux normes APA 7.
Prérequis
Ce document suppose une familiarité avec les notions de variable dépendante (VD) et de variable indépendante (VI), et avec la corrélation de Pearson. La lecture d'un nuage de points (scatterplot) dans JASP est un prérequis opérationnel. Le niveau visé est celui du BA1 : aucune connaissance antérieure du modèle linéaire ou du calcul des coefficients de régression n'est supposée. Tous les éléments nouveaux sont introduits à partir de l'intuition avant la formule, avec la définition explicite de chaque symbole.
Questions courantes FAQ
Quelle est la différence entre un modèle linéaire et une régression linéaire ?
Un modèle linéaire est une représentation mathématique de la relation entre deux variables sous la forme d'une droite (ŷ = b₀ + b₁x). La régression linéaire est la procédure statistique qui estime les paramètres de ce modèle à partir des données observées. Le modèle est une abstraction ; la régression est la méthode d'estimation. Cette distinction de terminologie est fondamentale pour une lecture précise des résultats.
Que signifie la pente b₁ dans un modèle de régression ?
La pente b₁ est le coefficient de proportionnalité entre le prédicteur et la variable dépendante. Elle indique de combien varie la valeur estimée de y lorsque x augmente d'une unité, toutes choses égales par ailleurs. Une pente de 2,25 signifie qu'une heure supplémentaire d'étude est associée à une augmentation estimée de 2,25 points au score. C'est le paramètre central du modèle, et son interprétation doit toujours être rapportée dans les unités des variables.
Quelle est la différence entre une valeur observée et une valeur estimée ?
Une valeur observée (y) est une donnée réelle mesurée sur le terrain. Une valeur estimée (ŷ) est celle que le modèle prédit à partir de l'équation de régression. La différence entre ces deux valeurs est le résidu : ε = y − ŷ. Le résidu mesure l'écart entre la réalité et ce que le modèle prédit. Cette distinction est fondamentale : confondre y et ŷ revient à confondre le réel et sa représentation modélisée.
Que mesure le R² et comment l'interpréter ?
Le R² (coefficient de détermination) mesure la proportion de la variance de la variable dépendante expliquée par le prédicteur. Un R² de 0,563 signifie que 56,3 % de la variance du score est associée aux heures d'étude. Les 43,7 % restants correspondent à des sources de variation non captées par le modèle. Un R² élevé n'implique pas une relation causale et ne garantit pas que le modèle est bien spécifié.
Comment interpréter l'ordonnée à l'origine b₀ ?
L'ordonnée à l'origine b₀ est la valeur estimée de y lorsque x est égal à zéro. Son interprétation substantielle n'est pertinente que si x = 0 a un sens dans la réalité étudiée. Si ce n'est pas le cas — par exemple si aucun participant de l'étude n'étudie zéro heure — b₀ reste un paramètre technique de l'équation sans interprétation directement applicable au contexte de la recherche.