Comment lire et interpréter une régression linéaire en psychologie
Maîtrisez l'équation, les coefficients et les diagnostics pour analyser vos données de recherche en psychologie.
Présentation de la régression linéaire en psychologie
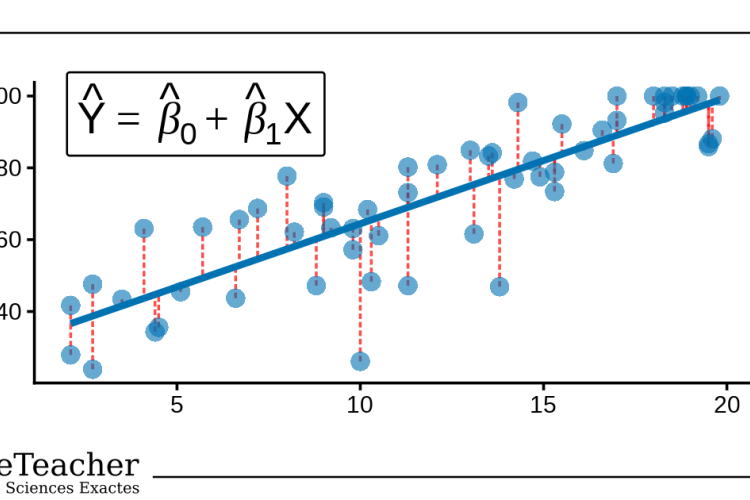
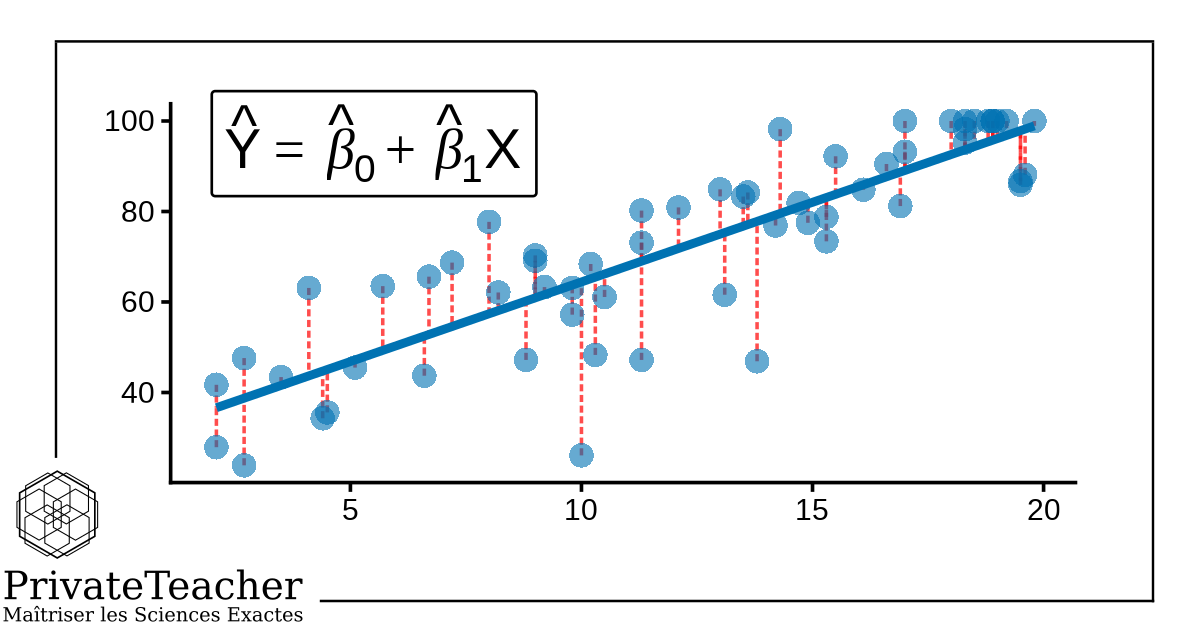
La régression linéaire est une méthode statistique qui modélise la relation entre une variable dépendante et une ou plusieurs variables indépendantes. En psychologie, elle permet de représenter des observations complexes sous la forme d'une équation simple. Cette équation est un modèle mathématique — une simplification de la réalité qui rend les données compréhensibles et exploitables. Plutôt que d'analyser chaque observation individuellement, la régression condense l'information en deux paramètres : la pente, qui exprime l'effet de X sur Y, et l'ordonnée à l'origine, qui donne la valeur de Y lorsque X vaut zéro. Cette approche s'inscrit dans le paradigme associatif de la psychologie quantitative : elle ne démontre pas de causalité, mais quantifie des associations entre variables mesurées sur des individus réels. La régression linéaire est aujourd'hui l'un des outils les plus utilisés en recherche psychologique empirique.
Pourquoi utiliser la régression linéaire en psychologie
La régression linéaire répond à des questions du type : dans quelle mesure le nombre de séances de thérapie prédit-il le score de qualité de vie ? Quel score à un examen peut-on attendre d'un étudiant qui consacre vingt heures par semaine à l'étude ? Elle permet d'estimer la valeur d'une variable critère à partir d'une ou plusieurs variables indépendantes, continues ou ordinales, et d'évaluer la significativité statistique de cette relation. En régression multiple, elle permet le contrôle statistique : comparer des groupes à niveau égal d'une troisième variable, ce qui est impossible avec une simple comparaison de moyennes. Elle est préférée aux tests de comparaison dans les designs observationnels où plusieurs variables agissent simultanément sur le critère mesuré. Elle produit des coefficients interprétables, une mesure d'ajustement (R²) et des diagnostics visuels.
A qui s'adresse ce cours
Ce document s'adresse aux étudiants en Bachelor de psychologie, en particulier à ceux qui suivent le cours STAT-II en deuxième année à l'Université de Lausanne (UNIL). La psychologie est une science empirique : les construits qu'elle étudie — bien-être, stress, efficacité thérapeutique — sont mesurés par des échelles et des questionnaires, puis analysés par des méthodes statistiques. La régression linéaire occupe une place centrale dans ce dispositif car elle permet de tester des hypothèses sur des relations entre variables psychologiques, de contrôler des variables confondantes et de produire des prédictions chiffrées. L'examen final du cours STAT-II requiert de savoir lire une sortie logicielle R, interpréter des coefficients et formuler une réponse argumentée. Ce document prépare directement à cet exercice, en articulant la méthode générale et plusieurs cas particuliers progressifs.
Prérequis
Ce document suppose une familiarité de base avec R et avec les concepts statistiques élémentaires : moyenne, variance, test d'hypothèse et valeur p. Une connaissance préalable du test t ou de l'ANOVA est un atout mais n'est pas indispensable. Aucune compétence en calcul différentiel ni en algèbre linéaire n'est requise : la régression est présentée de manière graphique et conceptuelle, sans dérivation formelle. Le niveau cible correspond au deuxième semestre de Bachelor en psychologie. Les notions de variable dépendante, variable indépendante et échelle de mesure sont supposées connues. Le lecteur doit être capable de lire un script R simple et de comprendre la sortie de la fonction summary(lm(...)). Ce document n'est pas adapté à des étudiants sans aucune exposition préalable aux statistiques ; il constitue un support de révision efficace avant un examen à développement.
Questions courantes FAQ
À quoi sert l'ordonnée à l'origine dans la régression ?
L'ordonnée à l'origine représente la valeur prédite de Y lorsque toutes les variables indépendantes valent zéro. En pratique, cette valeur est souvent hors du domaine observé et n'a pas d'interprétation directe. Son rôle principal est de positionner la droite dans le plan : c'est un paramètre d'ajustement indispensable à la définition du modèle, même lorsqu'il ne peut pas être interprété de manière substantielle.
Quelle est la différence entre R² et R² ajusté ?
Le R² mesure la proportion de variance de Y expliquée par le modèle. Le R² ajusté pénalise chaque variable indépendante ajoutée : il diminue si une variable n'apporte pas d'information réelle. En régression multiple, le R² ajusté est préférable car il évite de surestimer la qualité du modèle simplement en augmentant le nombre de variables indépendantes dans l'équation.
Comment vérifier que les résidus sont distribués normalement ?
Le QQ-plot compare la distribution des résidus standardisés à une distribution normale théorique : si les points s'alignent sur la droite, la normalité est confirmée. Le test de Shapiro-Wilk fournit une p-valeur formelle. En complément, la médiane des résidus doit être proche de zéro et la distribution doit être approximativement symétrique entre la queue gauche et la queue droite.
Que signifie contrôle statistique dans une régression multiple ?
Le contrôle statistique signifie que l'effet estimé d'une variable indépendante est calculé à valeur constante de toutes les autres. En incluant le genre et le nombre de séances dans le modèle, le coefficient du nombre de séances mesure son effet indépendamment du genre. Cela permet de comparer des individus qui diffèrent sur une variable tout en maintenant les autres constantes — impossible avec une simple corrélation bivariée.
Qu'est-ce qu'une variable dummy et comment l'interpréter dans R ?
Une variable dummy code une appartenance catégorielle en 0 ou 1. Dans une régression multiple, son coefficient représente la différence moyenne entre les deux groupes à valeur constante des autres variables. Graphiquement, elle produit deux droites parallèles de même pente mais d'ordonnées à l'origine décalées. Ce décalage quantifie l'effet du groupe toutes choses égales par ailleurs, et se lit directement dans la sortie de summary(lm(...)) sous R.