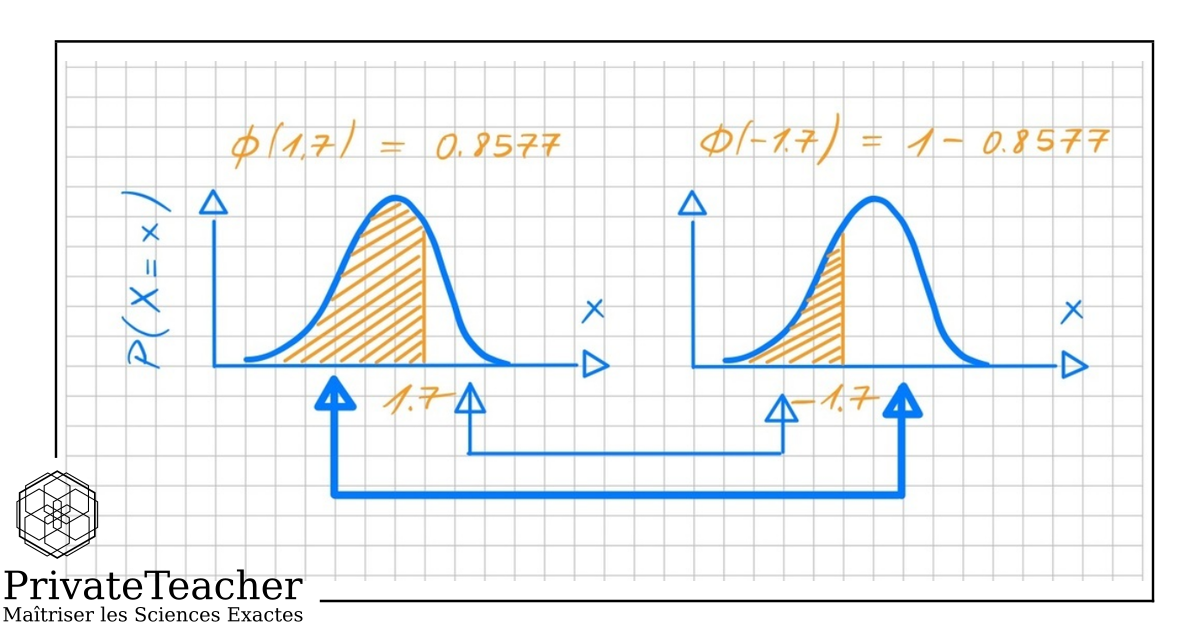
Introduction Chi2 et Test d'Indépendance
Introduction au test d'Indépendance et à la statistique du Chi-Carré
Apprends comment calculer le Chi2 à partir d'un tableau de contingence et à interpréter le résultats d'un test d'indépendance.
Présentation
Le Chi2 est une statistique de test conçue pour mesurer l'écart entre des effectifs observés et des effectifs théoriques. Il s'applique à des variables catégorielles organisées dans une table de contingence. Les modalités de la première variable se trouve sur une ligne alors que les modalité se trouve sur la seconde. Chaque cellule se trouve donc au croisement de deux modalité, pour cette raison, on appel aussi ces tables des tableau croisé. Le Chi2 quantifie à quel point les valeurs observée s'éloignent des valeurs que l'on observerai si les deux variables étaient indépendante. Plus cet écart est grand, plus la valeur du Chi2 est élevée.
Pourquoi utiliser le Chi2 et le Test d'Indépendance
Le test d'indépendance répond à la question suivante: deux variables catégorielles sont-elles liées ? Autrement dit: l'observation de la première variable me permet-elle de déduire la valeur de la deuxième ? Il s'agit là d'une question fréquente dans le domaine des sciences sociales, de la biologie et de la gestion: le genre influence-t-il le choix d'une filière ? Un traitement modifie-t-il le taux de réponse ? Le Chi2 fournit une mesure objective de cet écart et permet donc si l'association entre deux variables catégorielles est statistiquement significative.
A qui s'adresse ce document
Ce document s'adresse aux étudiants de Bachelor 1 qui rencontre le test du Chi2 pour la première fois, quelle que soit sa filière. Le test d'indépendance est utilisé dans de nombreux cursus : sciences sociales, psychologie, gestion, économie, biologie. . C'est souvent le premier test d'hypothèse qu'un étudiant applique à des données de type catégoriel.
Ce que contient ce document
Dans ce document, tu apprendras comment calculer les effectifs théoriques à partir d'une table de contingence. Ce document présente la formule du Chi2 à l'aide d'un exemple complet et démontre tous le détail des calculs étape par étape. Il explique comment déterminer les degrés de liberté et comment lire la table des quantiles du Chi2. Ce document introduit enfin le V de Cramer comme mesure de la taille d'effet.
Prérequis nécessaire
Le niveau requis pour lire ce document est celui du gymnase ou équivalent. Aucune connaissance préalable en statistiques n'est nécessaire. Ce document nécessite donc des connaissances d'algèbre élémentaire telle que savoir effectuer des opérations sur des fraction ou lire une table numérique. Les notions d'hypothèse statistique, d'effectif observé et d'effectif théorique sont définies dans le document avant d'être utilisées. Aucun logiciel n'est requis pour suivre le raisonnement : tous les calculs sont conduits à la main.
Questions courantes FAQ
Qu'est-ce qu'un tableau de contingence ?
Un tableau de contingence est une manière d'organiser les observation simultanée de deux variables catégorielles. Chaque ligne correspond aux modalités de la première variable, chaque colonne aux modalité de la seconde. Chaque cellule du tableau se trouve au croisement de deux modalité. Elle contient donc effectif observés pour la combinaison de ces deux modalité. Le tableau de contingence est le point de départ pour le calcul du Chi2.
Comment calculer les effectifs théoriques ?
L'effectif théorique est l'effectif que l'on observerait si les deux variables étaient totallement indépendantes. Il se calcule en multipliant le total marginal de la ligne par le total marginal de la colonne correspondante, puis en divisant par l'effectif total de l'échantillon. Ces valeurs théoriques servent de référence : le Chi2 mesure l'écart entre ces valeurs et les effectifs réellement observés.
Que mesure exactement le Chi2 ?
Le Chi2 mesure l'écart totale entre les effectifs observés et les effectifs théoriques dans le tableau. Pour chaque cellule, il calcule (observé − théorique)² puis le divise par la valeur théorique. La somme de ces termes sur toutes les cellules donne le Chi2 total. Une valeur proche de zéro indique que les données s'écartent peu de l'indépendance. Une valeur élevée signale un écart important.
Qu'est-ce que l'hypothèse nulle dans un test d'indépendance ?
Dans un test d'indépendance par le Chi2, l'hypothèse nulle H₀ est l'hypothèse selon laquelle les deux variables catégorielles sont indépendantes: la distribution d'une variable ne dépend pas des modalités de l'autre. Dit autrement, sous l'hypothèse nulle, connaitre la valeur d'une variable ne nous permet pas de déduire la valeur de la second. L'hypothèse alternative H₁ postule au contraire qu'une association existe. Comme tout test d'hypothèse cependant, le test ne prouve pas H₀ : il évalue si les données fournissent une preuve suffisante pour la rejeter.
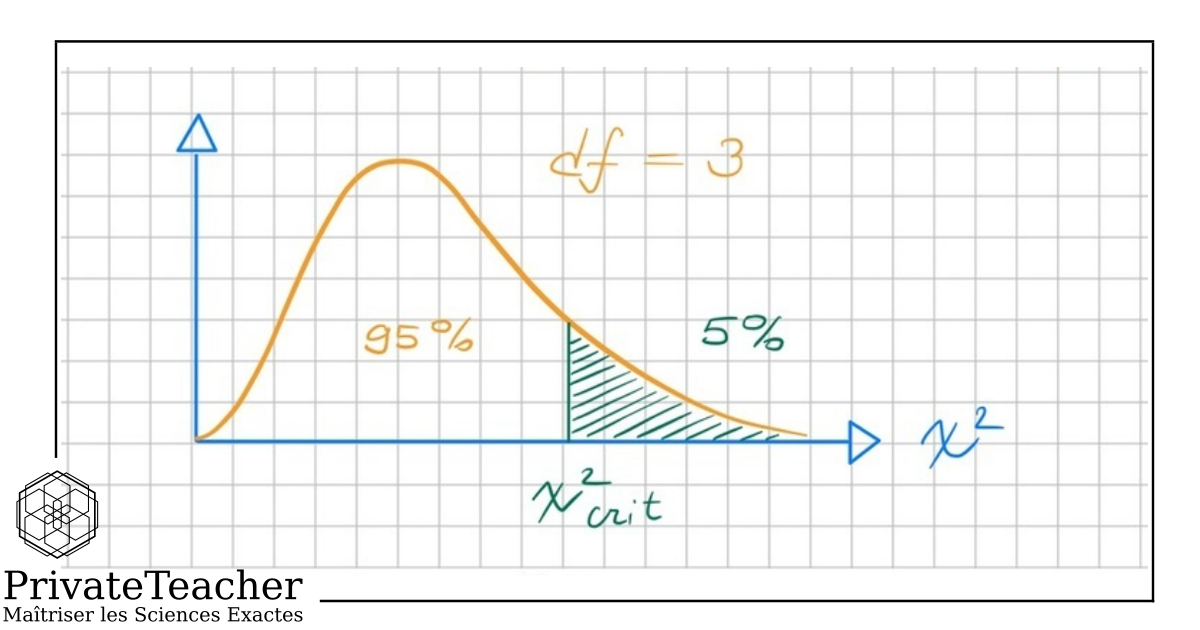
Comment utilise-t-on la table du Chi2 pour prendre une décision ?
La table du Chi2 donne la valeur critique pour un seuil α et un nombre de degrés de liberté. Les degrés de liberté valent (lignes − 1) × (colonnes − 1). Si le Chi2 calculé dépasse cette valeur critique, cela signifie que l'écart observé est significatif.
Qu'est-ce que le V de Cramer et pourquoi en a-t-on besoin ?
Le V de Cramer est un Chi2 normalisé. Le Chi2 en effet est sensible à la taille de l'échantillon : il croît mécaniquement avec n. Le V de Cramer normalise cette valeur pour obtenir un indice compris entre 0 et 1. On l'interprète de la manière suivante: 0 signifie absence d'association, 1 signifie association parfaite. C'est la mesure de taille d'effet associée au test du Chi2.
Cours PDF | ||